OpenAI’s o3 suggests AI models are scaling in new ways — but so are the costs
Last month, AI founders and investors told TechCrunch that we’re now in the “ second era of scaling laws, ” noting how established methods of improving AI models were showing diminishing returns. One promising new method they suggested could keep gains was “ test-time scaling ,” which seems to be what’s behind the performance of OpenAI’s o3 model – but it comes with drawbacks of its own.
Much of the AI world took the announcement of OpenAI’s o3 model as proof that AI scaling progress has not “hit a wall.” The o3 model does well on benchmarks, significantly outscoring all other models on a test of general ability called ARC-AGI, and scoring 25% on a difficult math test that no other AI model scored more than 2% on.
Of course, we at TechCrunch are taking all this with a grain of salt until we can test o3 for ourselves (very few have tried it so far). But even before o3’s release, the AI world is already convinced that something big has shifted.
The co-creator of OpenAI’s o-series of models, Noam Brown, noted on Friday that the startup is announcing o3’s impressive gains just three months after the startup announced o1 – a relatively short timeframe for such a jump in performance.
We announced @OpenAI o1 just 3 months ago. Today, we announced o3. We have every reason to believe this trajectory will continue. pic.twitter.com/Ia0b63RXIk
— Noam Brown (@polynoamial) December 20, 2024
“We have every reason to believe this trajectory will continue,” said Brown in a tweet .
Anthropic co-founder Jack Clark said in a blog post on Monday that o3 is evidence that AI “progress will be faster in 2025 than in 2024.” (Keep in mind that it benefits Anthropic – especially its ability to raise capital – to suggest that AI scaling laws are continuing, even if Clark is complementing a competitor.)
Next year, Clark says the AI world will splice together test-time scaling and traditional pre-training scaling methods to eke even more returns out of AI models. Perhaps he’s suggesting that Anthropic and other AI model providers will release reasoning models of their own in 2025, just like Google did last week .
Test-time scaling means OpenAI is using more compute during ChatGPT’s inference phase, the period of time after you press enter on a prompt. It’s not clear exactly what is happening behind the scenes: OpenAI is either using more computer chips to answer a user’s question, running more powerful inference chips, or running those chips for longer periods of time – 10 to 15 minutes in some cases – before the AI produces an answer. We don’t know all the details of how o3 was made, but these benchmarks are early signs that test-time scaling may work to improve the performance of AI models.
While o3 may give some a renewed belief in the progress of AI scaling laws, OpenAI’s newest model also uses a previously unseen level of compute, which means a higher price per answer.
“Perhaps the only important caveat here is understanding that one reason why O3 is so much better is that it costs more money to run at inference time – the ability to utilize test-time compute means on some problems you can turn compute into a better answer,” Clark writes in his blog. “This is interesting because it has made the costs of running AI systems somewhat less predictable – previously, you could work out how much it cost to serve a generative model by just looking at the model and the cost to generate a given output.”
Clark, and others, pointed to o3’s performance on the ARC-AGI benchmark – a difficult test used to assess breakthroughs on AGI – as an indicator of its progress. It’s worth noting that passing this test, according to its creators, does not mean an AI model has achieved AGI, but rather it’s one way to measure progress towards the nebulous goal. That said, the o3 model blew past the scores of all previous AI models which had done the test, scoring 88% in one of its attempts. OpenAI’s next best AI model, o1, scored just 32%.
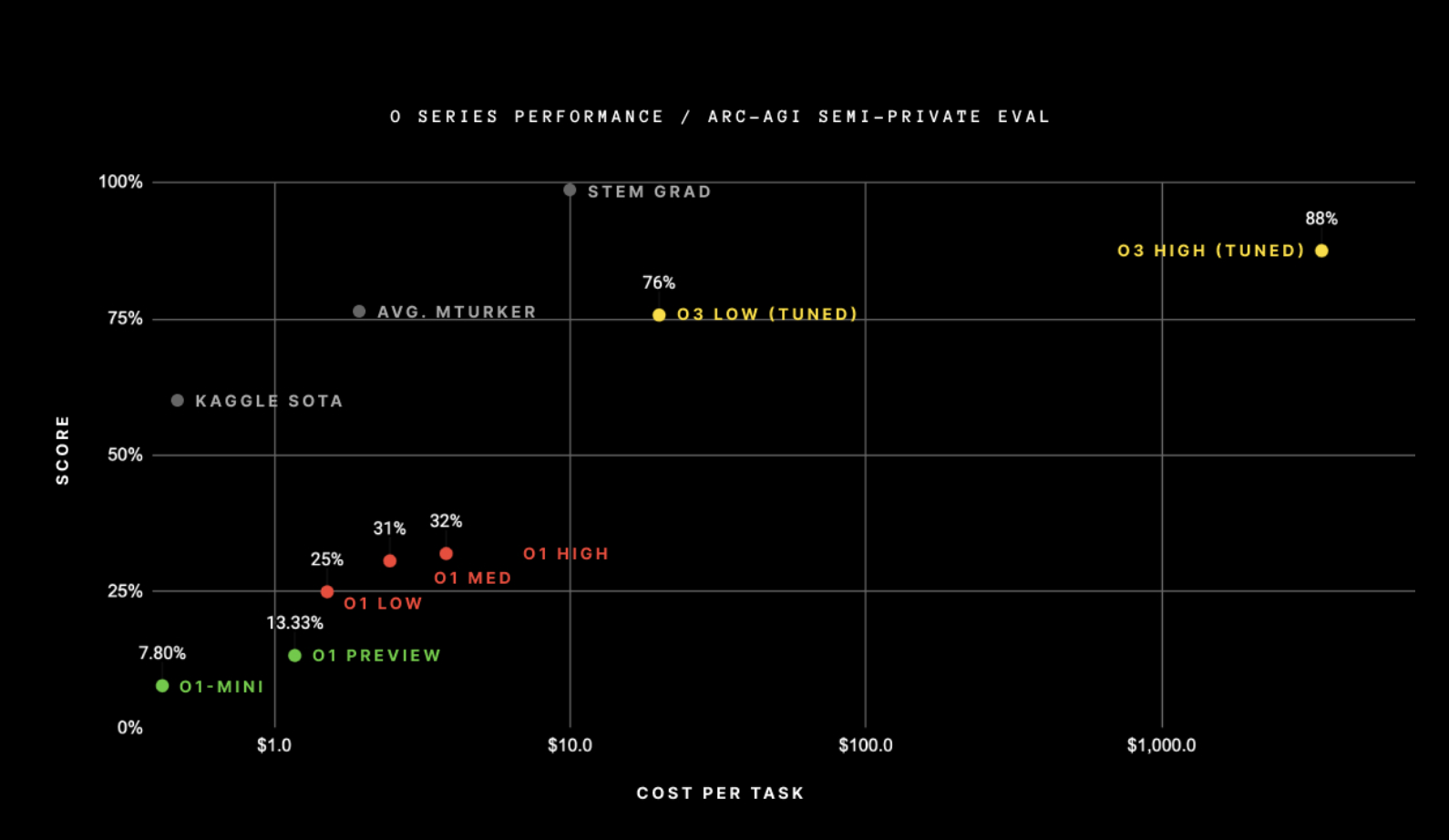
But the logarithmic x-axis on this chart may be alarming to some. The high-scoring version of o3 used more than $1000 worth of compute for every task. The o1 models used around $5 of compute per task, and o1-mini used just a few cents.
The creator of the ARC-AGI benchmark, François Chollet, writes in a blog that OpenAI used roughly 170x more compute to generate that 88% score, compared to high-efficiency version of o3 that scored just 12% lower. The high-scoring version of o3 used more than $10,000 of resources to complete the test, which makes it too expensive to compete for the ARC Prize – an unbeaten competition for AI models to beat the ARC test.
However, Chollet says o3 was still a breakthrough for AI models, nonetheless.
“o3 is a system capable of adapting to tasks it has never encountered before, arguably approaching human-level performance in the ARC-AGI domain,” said Chollet in the blog. “Of course, such generality comes at a steep cost, and wouldn’t quite be economical yet: you could pay a human to solve ARC-AGI tasks for roughly $5 per task (we know, we did that), while consuming mere cents in energy.”
It’s premature to harp on the exact pricing of all this – we’ve seen prices for AI models plummet in the last year, and OpenAI has yet to announce how much o3 will actually cost. However, these prices indicate just how much compute is required to break, even slightly, the performance barriers set by leading AI models today.
This raises some questions. What is o3 actually for? And how much more compute is necessary to make more gains around inference with o4, o5, or whatever else OpenAI names its next reasoning models?
It doesn’t seem like o3, or its successors, would be anyone’s “daily driver” like GPT-4o or Google Search might be. These models just use too much compute to answer small questions throughout your day such as, “How can the Cleveland Browns still make the 2024 playoffs?”
Instead, it seems like AI models with scaled test-time compute may only be good for big picture prompts such as, “How can the Cleveland Browns become a Super Bowl franchise in 2027?” Even then, maybe it’s only worth the high compute costs if you’re the general manager of the Cleveland Browns, and you’re using these tools to make some big decisions.
Institutions with deep pockets may be the only ones who can afford o3, at least to start, as Wharton professor Ethan Mollick notes in a tweet.
O3 looks too expensive for most use. But for work in academia, finance & many industrial problems, paying hundreds or even thousands of dollars for a successful answer would not be we prohibitive. If it is generally reliable, o3 will have multiple use cases even before costs drop
— Ethan Mollick (@emollick) December 22, 2024
We’ve already seen OpenAI release a $200 tier to use a high-compute version of o1 , but the startup has reportedly weighed creating subscription plans costing up to $2,000. When you see how much compute o3 uses, you can understand why OpenAI would consider it.
But there are drawbacks to using o3 for high-impact work. As Chollet notes, o3 is not AGI, and it still fails on some very easy tasks that a human would do quite easily.
This isn’t necessarily surprising, as large language models still have a huge hallucination problem , which o3 and test-time compute don’t seem to have solved. That’s why ChatGPT and Gemini include disclaimers below every answer they produce, asking users not to trust answers at face value. Presumably AGI, should it ever be reached, would not need such a disclaimer.
One way to unlock more gains in test-time scaling could be better AI inference chips. There’s no shortage of startups tackling just this thing, such as Groq or Cerebras, while other startups are designing more cost-efficient AI chips, such as MatX. Andreessen Horowitz general partner Anjney Midha previously told TechCrunch he expects these startups to play a bigger role in test-time scaling moving forward.
While o3 is a notable improvement to the performance of AI models, it raises several new questions around usage and costs. That said, the performance of o3 does add credence to the claim that test-time compute is the tech industry’s next best way to scale AI models.


